Annotations
What is image annotation?
Image annotation is the foundation of supervised learning (SL) artificial intelligence (AI) and the procedure of adding labels to images.
Labels are used to represent features that deep learning (DL) models need to recognize (e.g. Which objects does the image represent?
Where are they located in the image?).
Usually, a data labeler uses tags or metadata to identify and define characteristics of the image data you want the computer vision (CV)
model to learn to recognize. Accurate labelling is one of the foundations for a precise CV model.
Categories of image annotations:
Different types of annotations are used to mark different features or properties of the image content. Depending on the use case and CV
task at hand (object recognition, object detection, image segmentation), one of the following annotations is used to label the image dataset:
- 2D/3D bounding-box
- Pixel wise polygons
- Class segmentation
- Instance segmentation
In 3D computer vision applications, additional annotation channels are used, which would also be provided by a classic industrial 3D
sensor in a real environment: - Surface normal
- XYZ-depth information (point cloud)
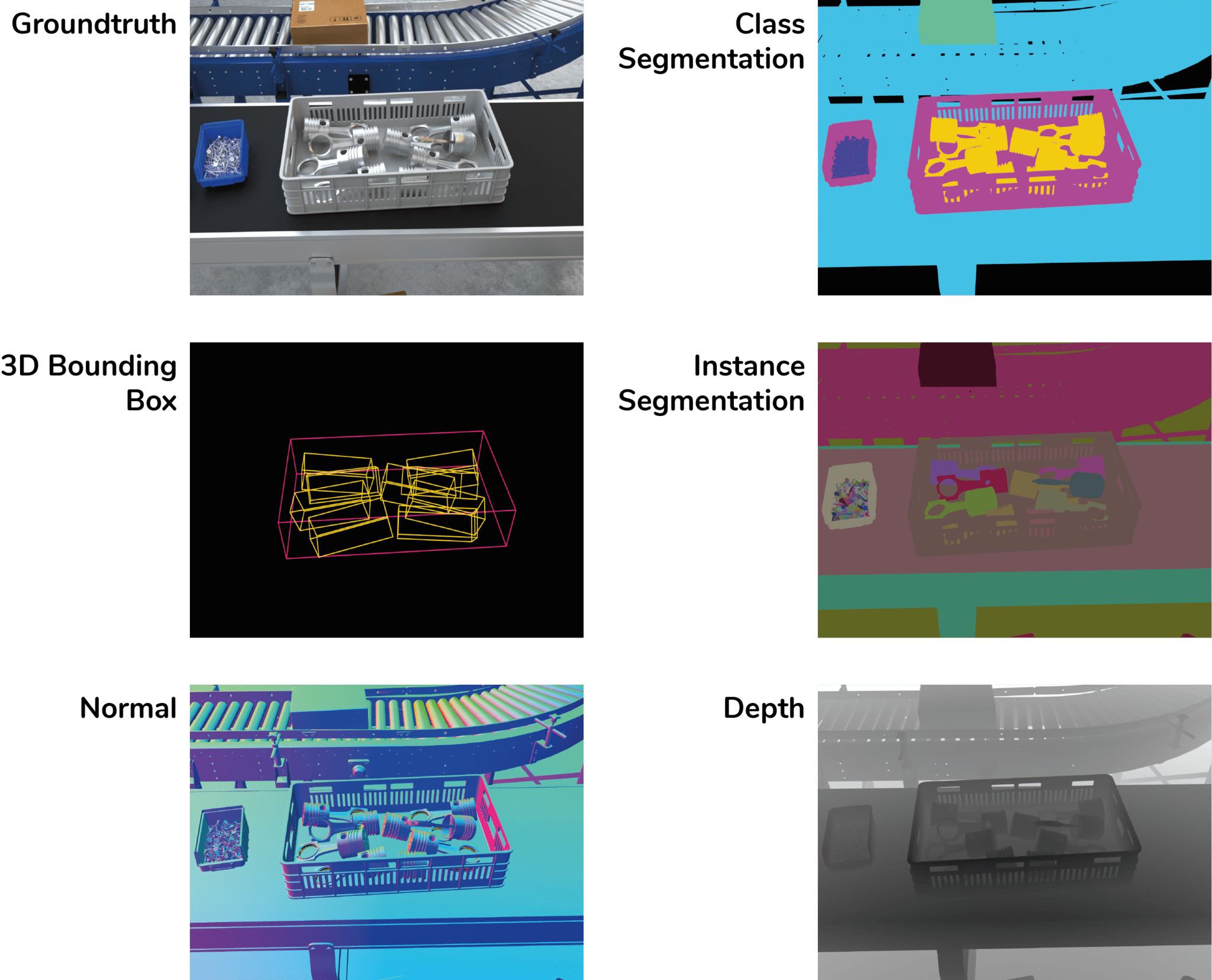
Synthetic (computer generated) examples of common annotation types (groundtruth, 3D bounding box, class segmentation, instance segmentation, normal, depth).
Challenges in common Annotation methods:
- Organizational overhead and costs
During the labeling process where people manually tag images, there are costs associated with man power and management required
to annotate large datasets. - Human in the loop
When image annotation is done by humans, the dataset is prone to human error and bias, when it comes to the consistency of the
labels. Even in case of annotation software tools that are automated to a certain degree, the tools rely on human input as a basis.
Since errors from biased opinions can be costly, domain experts are sometimes the only source of high quality annotated image data. - Consistently high accuracy over the dataset
Common problems are inaccurate or missing labels – in both cases the computer vision (CV) algorithm would learn from misinformation
and never reach required precision levels. Such inaccuracy can be the source of issues such as false positives.
Synthetic image data as an alternative:
Thanks to the creation process of synthetic data, no more manual labelling work is required.
While generating synthetic data, the process for gathering the label data is completely different from manual annotation. Since the represented scene is simulated in 3D, information such as the positions of features or objects is known at all times. This information only needs to be transferred and stored in the relevant annotation channels.
This approach allows us to consistently deliver high quality annotations through the whole dataset, with respect to your use case requirements.